Raspisivanje math-a
THIS IS A DRAFT
I'll probably just delete this!
Nagib linije
Recimo da imamo sljedeću funkciju: f(x) = x+1:
Želimo odrediti njezin nagib (slope). Nagib definiramo kao promjenu y u odnosu na promjenu x.
Nagib nam govori koliko brzo y raste ako promijenimo x.
- Odaberemo bilo koju točku (x1,y1) na grafu.
- Nakon toga x povećamo za proizvoljnu veličinu Δx, te pogledamo koliko iznosi promjena Δy.
- Tako dobivamo drugu točku, (x1+Δx, y1+Δy), odnosno (x2, y2).
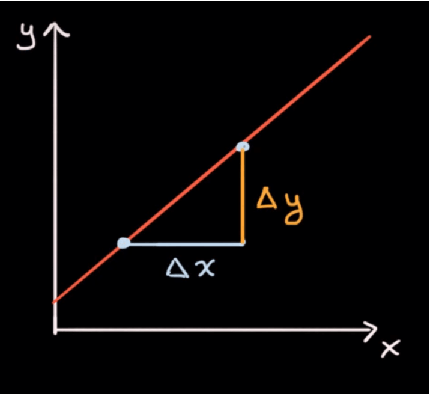
Nagib možemo izračunati tako što podijelimo promjenu na y osi sa promjenom na x osi.
(x2, y2) = (x1 + Δx, y1+Δy)
Δy / Δx = (y2 - y1) / (x2 - x1)
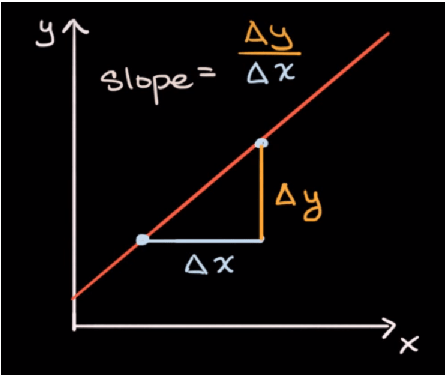
Pošto je ova funkcija linearna, vidimo da je nagib konstantan, kojegod dvije točke odabrali.
- Konkretno, uzmimo za primjer točku (0,1).
- Ako x koordinatu povećamo za 1 (Δx), y će iznositi 2 (Δy).
- x1 = 0, y1 = 1, x2 = 1, y2 = 2.
- Nagib ove funkcije, je stoga: Δy/Δx = (2 - 1) / (1 - 0) = 1.
Vidimo da je promjena y u odnosu na x jednaka, odnosno funkcija raste točno onoliko koliko smo promijenili x, linearna je, rast je konstantan i iznosi 1.
Ako imamo nelinearnu funkciju, kao ispod:
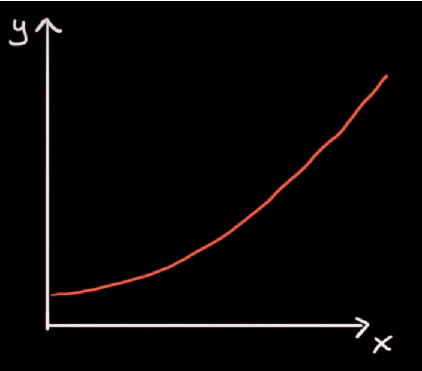
Možemo vidjeti da rast funkcije nije jednak u svim točkama. Primjerice, nagib (rast) na sljedeće dvije točke:
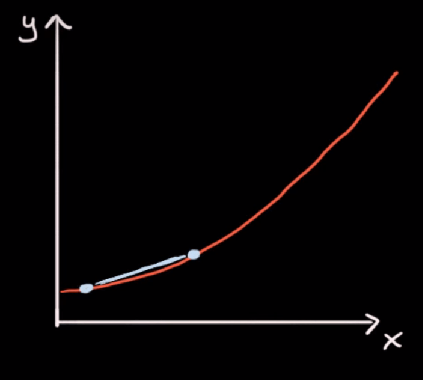
Nije jednak nagibu (rastu) na sljedeće dvije točke:
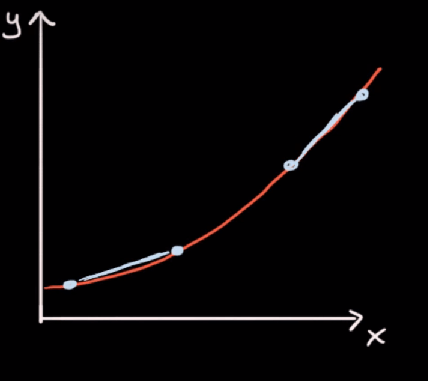
Na gornje dvije točke, nagib je veći, odnosno rast funkcije je brži. Postavlja se pitanje, kakav je nagib funkcije u pojedinoj točki, budući da se slijeva nadesno mijenja, odnosno povećava, rast funkcije raste.
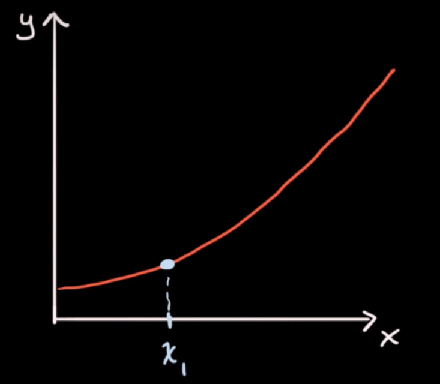
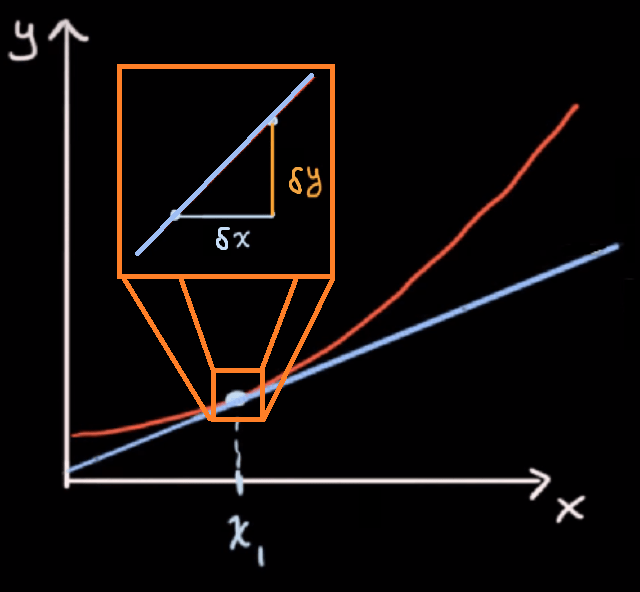
Budući da se nagib funkcije konstantno mijenja, iz točke u točku, odnosno raste, konkretan nagib na jednoj točki možemo odrediti pomoću nagiba tangente koja dodiruje graf funkcije u točno toj točki:
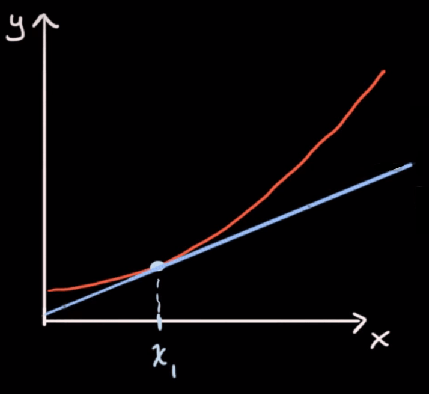
Nagib smo na linearnoj funkciji odredili tako što smo x pomakli za neku vrijednost Δx, izmjerili pomak Δy, te izračunali njihov omjer, odnosno razliku između početne točke i novo dobivene točke:
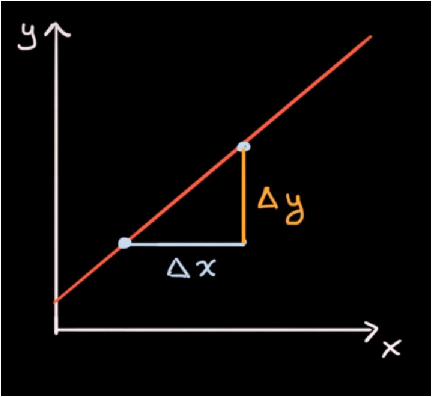
Ako na ovoj, nelinearnoj funkciji, zamislimo da je Δx jako, jako malen (malo delta: δx=x+ε, epsilon, infinitesimal), te izmjerimo isto malen pomak Δy (malo delta δy), dobit ćemo nagib funkcije u toj točki:
δy/δx - umjesto δ se često piše d, kao derivative (Leibnitzova notacija).
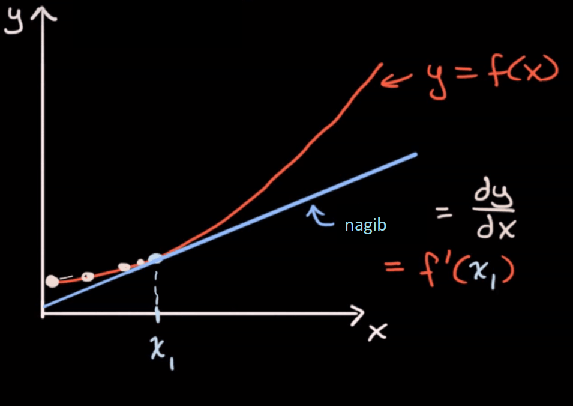
Ako je δx, jako mal (teži u nulu), dobijamo derivaciju (rast) funkcije u toj točki:
Derivacije
Uzmimo za primjer f(x) = x²:
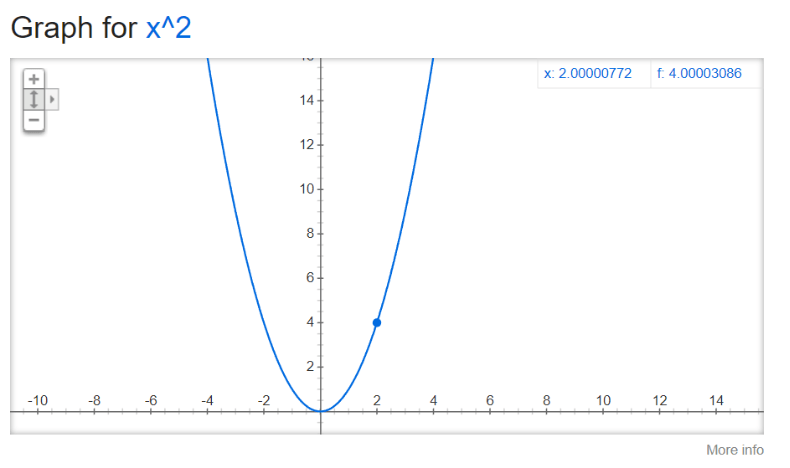
Znamo da za x=2, f(x) = x², f(2) iznosi 4. Ako x pomaknemo udesno za jako malen broj, 0.00000772, f(x) će se promijeniti na 4.00003086. Stoga:
δx = 0.00000772
δy = 0.00003086
δy/δx = 2.0000077 ~= 2 (zbog zaokruživanja)
Stoga možemo reći da je derivacija δy/δx=f’(x) = 2x:
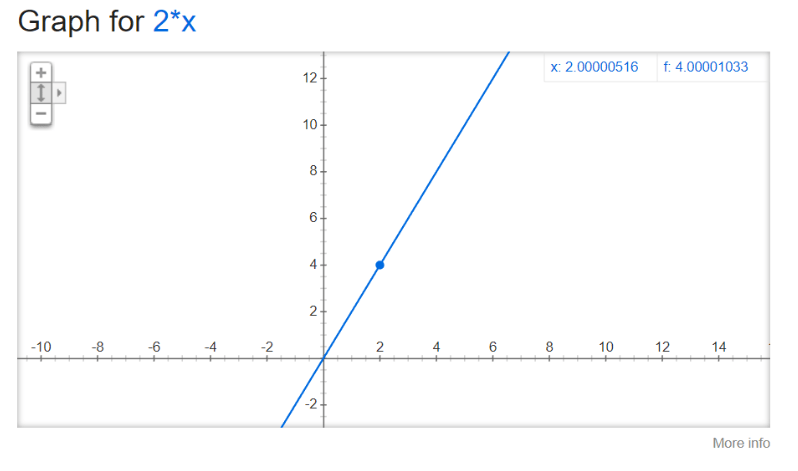
Što znači da u točki 2, derivacija f’(x) iznosi 2*x=4, odnosno y os će se promijeniti za dvostruku vrijednost promjene na x osi.
Ako se vratimo na prvu opisanu (linearnu)funkciju f(x) = x+1, vidjeli smo da je njezin rast konstantan, odnosno jedan, a derivacija iste te funkcije iznosi f’(x) = 1.
Parcijalne derivacije
Ako je funkcija multivariate, odnosno ovisi o više varijabli, primjerice: f(x,y) = -x² - y²
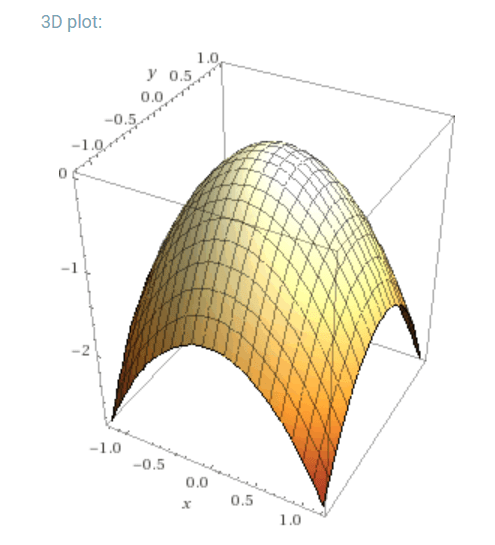
Kada deriviramo z = f(x,y) po jednoj od varijabli, drugu tretiramo kao konstantu, pa dobivamo sliku:
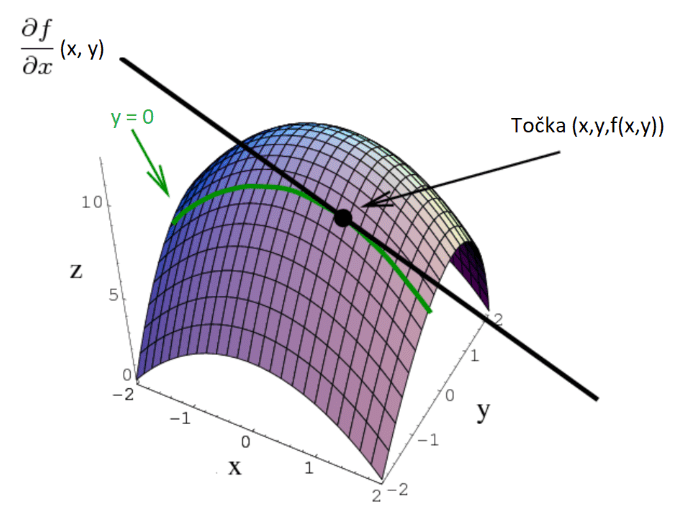
Ako napravimo derivaciju po drugoj osi (y-osi), dobivamo rast funkcije u točki (x,y) za tu os.
Svaka parcijalna derivacija je skalarna vrijednost, koja nam govori nagib tangente nad grafom funkcije u toj točki.
Ako sve parcijalne derivacije kombiniramo, dobivamo vektor [∂f/∂x, ∂f/∂y] (generalizira se na n-dimenzija) koji nam govori u kojem smjeru graf najbrže raste.
Drugi naziv za vektor [∂f/∂x, ∂f/∂y] je gradijent funkcije f.
Gradijent funkcije
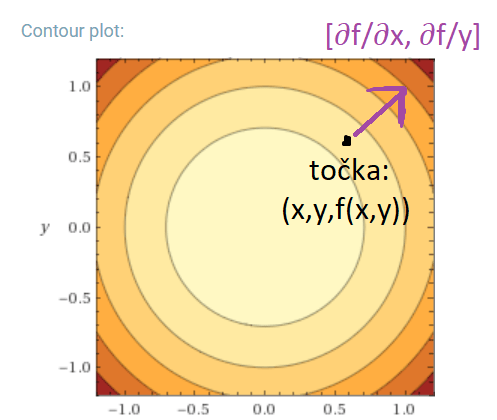
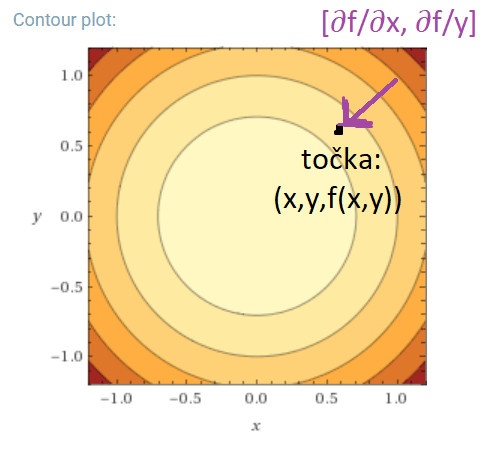
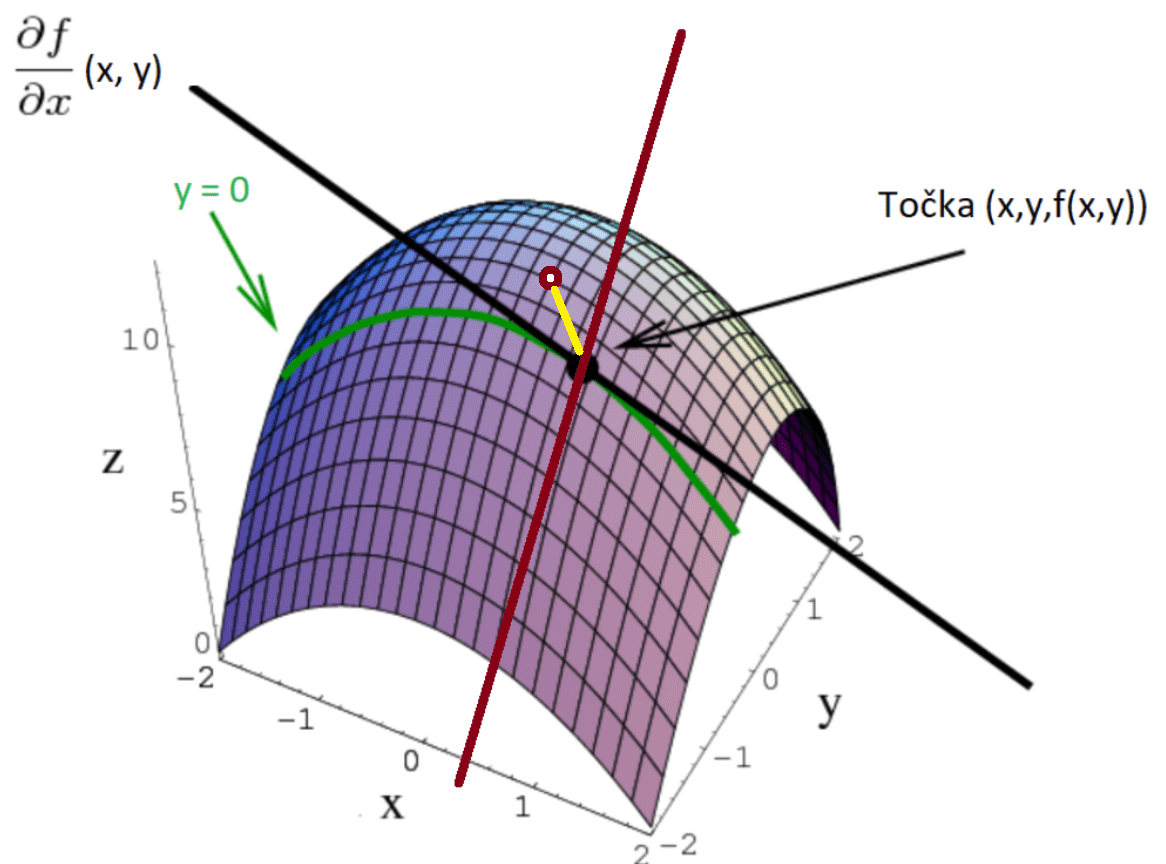
Uzmemo li contour plot za gore prikazani konveksni paraboloid i neku točku (x,y,f(x,y)), te izračunamo njezin gradijent, dobit ćemo vektor [∂f/∂x, ∂f/y] koji pokazuje smjer najbržeg rasta funkcije, najstrmiji nagib orijentiran prema rastu.
Ako taj vektor pomnožimo sa minus 1, dobijamo suprotan vektor [-∂f/∂x, -∂f/∂y], koji pokazuje najbrži smjer pada funkcije:
Note: vektori predstavljaju klase ekvivalencije, te je vektor sa gornje slike jednak vektorima sa sljedeće slike:
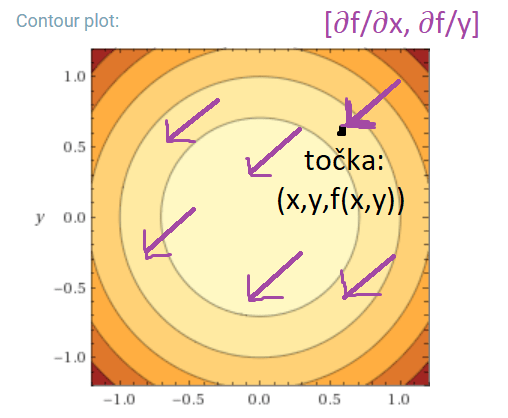
Svaki vektor predstavlja smjer u kojemu se trebamo kretati iz točke u kojoj smo računali gradijent, kako bi najbrže došli do najbližeg lokalnog minimuma f-je, koji je na grafu ujedno i globalni minimum, pošto je paraboloid konveksan.
Why
First things first, kako uopće dobit smjer gradijenta?
Uzmimo za primjer parcijalnu derivaciju po x, formula je: ∂f/∂x. Ova derivacija nam govori kako će se promijeniti f, ako x pomaknemo za neku malu vrijednost ∂x, govori nam rast/pad funkcije. Isto vrijedi i za ∂f/∂y, ako malo promijenimo y, za ∂y, govori nam za koliko će se promijeniti f.
Primjer koji možemo zamisliti da je gradijent [∂f/∂x, ∂f/y] = [2x, 3y-1]. Ako su ∂x i ∂y jako mali brojevi, blizu su nuli, pa unesemo (0,0) i dobivamo vektor [0, -1]. To je smjer gradijenta i ujedno i najbrži smjer rasta funkcije f.
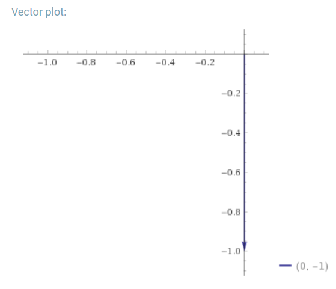
Da smo ubacili nekakav random vektor, primjerice (-1, -1), dobili bi vektor [-2, 4]:
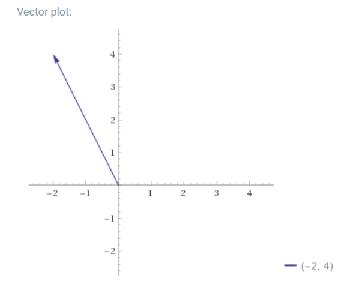
Ova dva vektora su skroz različita, gdje prvi pokazuje smjer najbržeg rasta, odnosno smjer gradijenta (usmjerenih derivacija), a drugi nekakav skroz random smjer. Ako želimo ići u smjeru gradijenta, samo uzmemo njegovu normu, odnosno zamislimo da smo uvrstili.
Isto tako, zamislimo da krećemo iz točke (x,y,f(x,y)), ako vrijednosti x i y promijenimo za ∂x i ∂y, doći ćemo u novu točku (crvena sa bijelim). Ako povežemo početnu točku sa novom točkom (x+∂x, y+∂y, f(x+∂x,y+∂y)), dobivamo vektor koji pokazuje smjer u kojemu se nalazi maksimum.
Sad zamislimo da imamo vektor a, smjer gradijenta, koji pokazuje točno u smjeru najbržeg rasta funkcije f. Ako uzmemo nekakav proizvoljan unit vektor b, koji pokazuje u random smjeru, zanima nas koliko smo “pogodili” smjer najbržeg rasta.

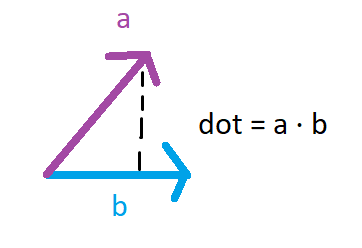
Dot produkt dva vektora nam u biti govori koliko su ta dva vektora slična, ako primjerice precrtamo a na b. Pitanje je kako odabrati vektor b koji je najsličniji vektoru a, koji pokazuje točno u smjeru rasta.
Najsličniji vektor, vektoru a, je sam taj vektor, jer je dot produkt dva ista vektora jednak 1, odnosno 100% su slični/isti.
Chain derivative rule
Ako imamo kompoziciju funkcija:
Konkretniji primjer
Uzmimo za primjer sljedeće funkcije:
Za f(x,y) napravimo obje parcijalne derivacije:
Chain derivative rule nam govori da možemo dobiti derivaciju funkcije f u odnosu na varijablu t:
Derivacija te naše kompozicije, po chain ruleu je onda jednaka:
Chain rule u backpropagationu
Recimo da imamo single hidden layer neural net:
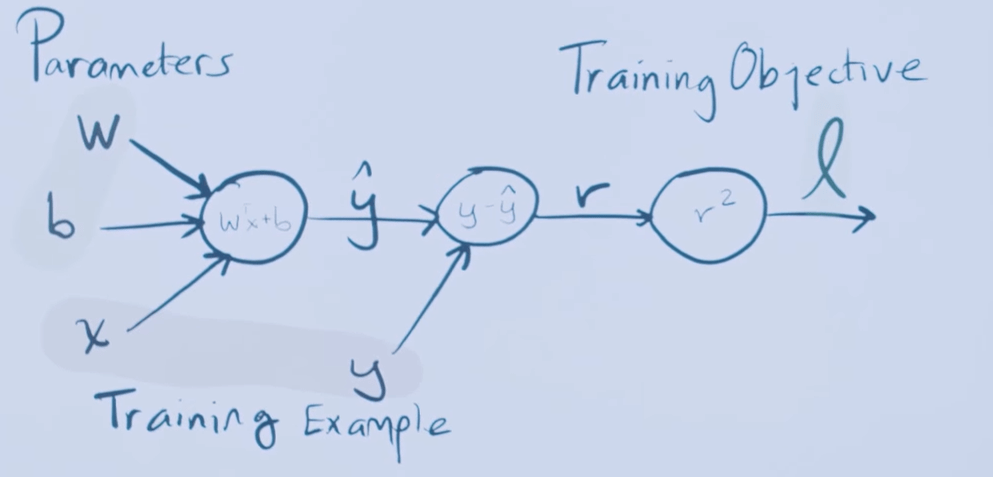
Loss funkciju definiramo kao:
Zamislimo da imamo sljedeći neural net:
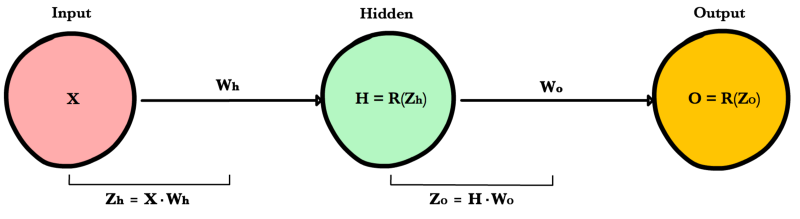
Definiramo cost funkciju za ovaj net kao:
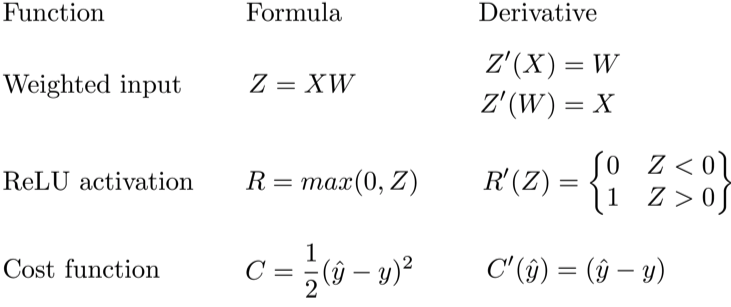
Pomoću chain rulea, možemo lako odrediti koliko točno koji weight utječe na grešku koju naš neural net radi. Kad parcijalno deriviramo cost function po jednom od parametara, sve ostale tretiramo kao konstante, pa možemo odrediti kako mijenjanje određenog parametar (dimenzija) utječe na rast i pad naše funkcije (cost funkcije).
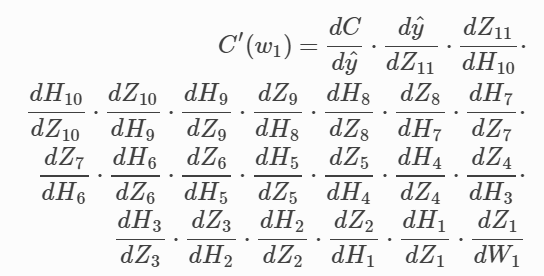
Također, kad računamo derivaciju za n-ti sloj, koristimo sve derivacije koje smo koristili za sloj n+1, samo dodajući par potrebnih derivacija za sloj iznad. Puno posla se ponavlja:
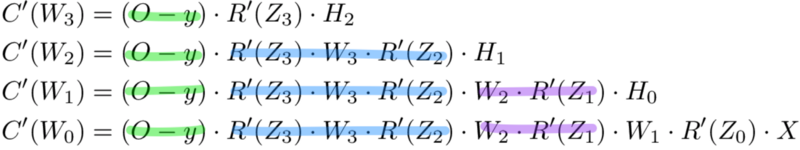
Kako to olakšat?
Layer error označava derivaciju cost funkcije u odnosu na input pojedinog layera. Odgovara na pitanje: kako se rezultat cost funkcije mijenja kad malo promijenimo input u tom layeru.
Prvo izračunamo output layer error, i taj rezultat proslijedimo hidden layeru prije njega.
Nakon što izračunamo layer error tog hidden layera, vratimo njegovu vrijednost hidden layeru prije njega, itd, sve dok ne dođemo do input layera.
Slika za lakši reference:
Output layer error
Zanima nas derivacija cost funkcije u odnosu na ulaz (input) output layera: $Z_o$.
Ta derivacija nam govori kako promjena weightova između zadnjeg hidden layera i output layera utječe na rezultat cost funkcije:
Hidden layer error
Zanima nas derivacija cost funkcije u odnosu na input koji hidden layer prima: